Homework 2: Pipelined Processors in Ripes
Due: Friday, 2/21 at 10pm
Overview
In class, we implemented a single-stage CPU in Ripes, and then used the concept of instruction-level parallelism to create a five-stage pipelined CPU. In this assignment, you will explore the consequences of creating four- and six- stage CPUs. You will identify data and control hazards, implement the forwarding and hazard units for the CPUs, and perform some analysis about the relative performance of the pipelines.
Note: the Autograder will become available before 2/10.
Stencil code
We will be working in our course Ripes repo, which is already on the Docker containers in the provided dev environment. Important: perform a git pull in the Ripes directory to pull in the latest code (a commit on 2/6 updated the starter code with a modified 6s pipeline from what exists in the course docker). Just like in HW1, build Ripes using make (optionally with -j4 or -j8 to speed it up). The files you will be working on are in the src/processors/CS1952y/four_stage_cpu and src/processors/CS1952y/six_stage_cpu subdirectories. The processor circuits, including the completed decode/control units from the single-stage processor, are provided for you. You will be completing the hazard and forwarding units. Remember that all of the code for the single-stage and five-stage CPUs we built in class, including intermediate steps, has been provided for you in this repo, as a reference.
Don’t forget the Ripes/RISC-V resources linked on the course page, and the lecture notes linked on the schedule page! Before starting the homework, read through part 3 of the pipelining notes this is “Part 0” of the homework and gives context to the forwarding units you will be implementing.
Grading information
You will be graded on the functionality and performance of your hazard and forwarding units, as well as your analysis. See the handin section for a list of files to turn in. We expose some basic Autograder tests, but it’s up to you to thoroughly test your pipelines for how they respond to hazards. Keep in mind that the actual amount of code you have to write for this assignment is not that high: the majority of the time spent will be reasoning about hazards and resolving design decisions.
The processors should be able to handle every instruction on page 104 of the RISC-V spec (the 32I base instruction set table) except for FENCE, FENCE.I, ECALL, EBREAK, CSRRW CSRRS, CSRRC, CSRRWI, CSRRSI, CSRRCI.
The pipelines
Four-stage pipeline: This processor gets rid of the ID stage, putting the decoding and control into the “I” (previously IF) stage, and the register file write/read into the Ex stage. Reading from the register file is assumed to be fast, so moving the register file to the execute stage might make sense if the memory operations (on data/instruction memory) are the bottleneck.
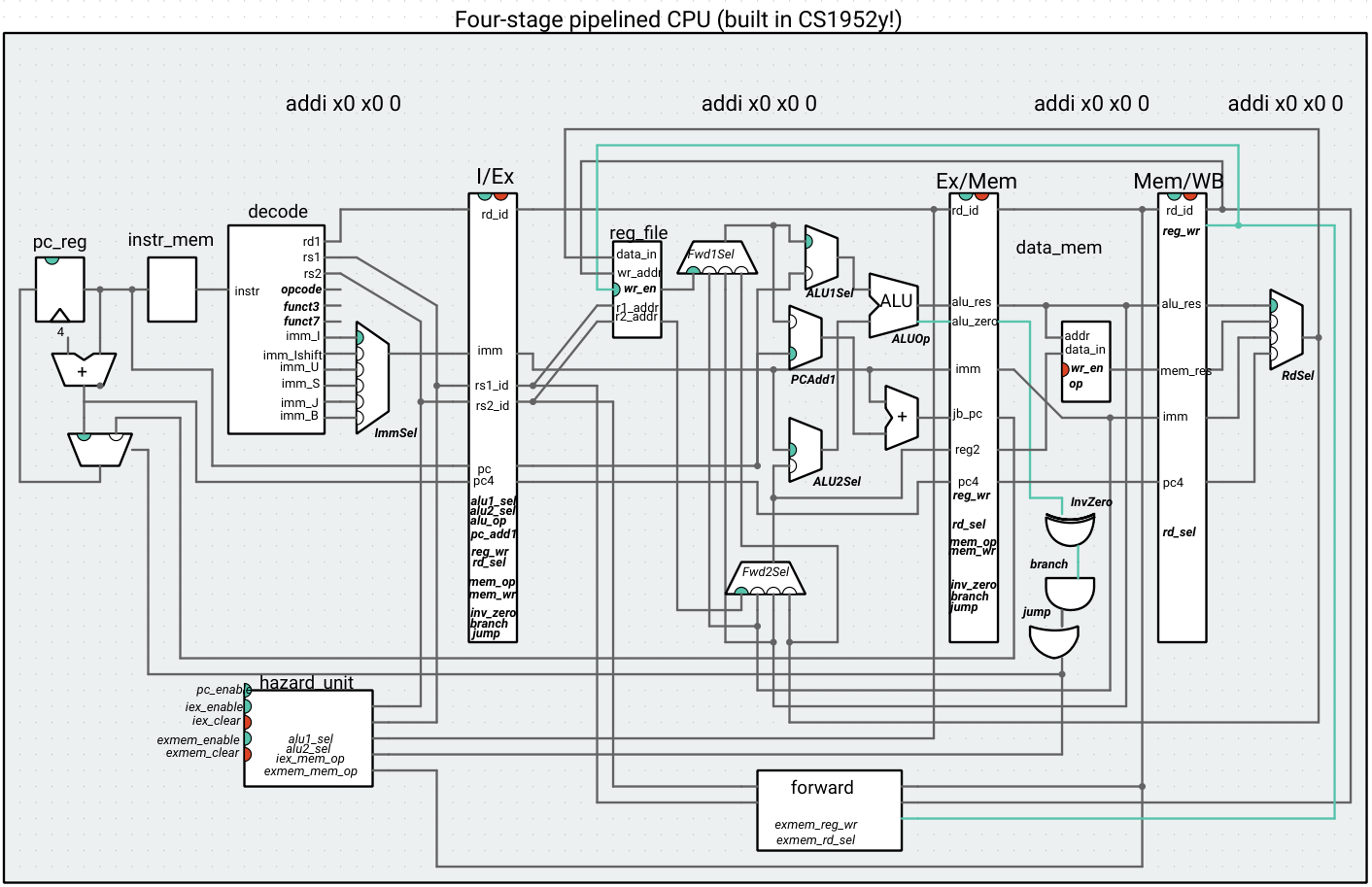
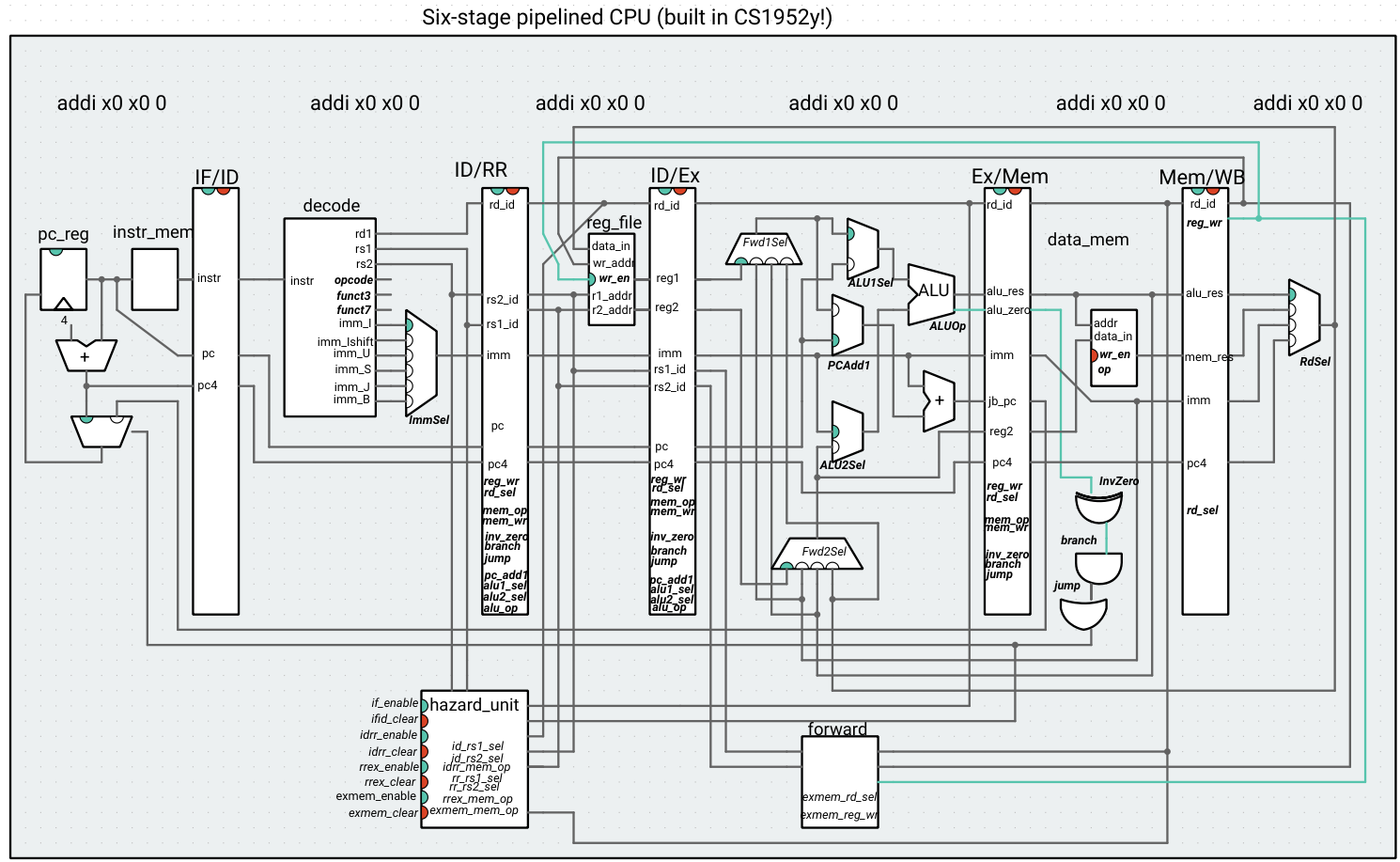
Six-stage pipeline: This processor attempts to compensate for the fact that memory read/writes might be slow by pipelining the memory unit (we’ll start exploring other ways to increase memory access throughput in class). Memory is split into two stages. An instruction requests a memory access in Mem1, and receives the result after the subsequent cycle. This might mean that two load/store instructions are using the data memory unit at one time (one in Mem1, the other in Mem2). However, we assume that these accesses will happen in order, e.g. a store followed by a load at the same address will not introduce a hazard.
Tips
There are a lot of wires and signals in the images above. Don’t panic! These are complicated circuit because CPUs are complicated little pieces of electronics (in fact, as we’ll see, modern processors even more so), but here are some tips to navigate the circuitry:
- Just like we did in class, you can trace an instruction by looking at the control signals that are high (look at the highlighted indicator on each multiplexer). Get to know each processor by running a few instructions at a time and observing their journey through the pipeline.
- If you don’t know where a wire goes, click on it to highlight it. You can also take a look at the
cs1952y4s_cpuandcs1952y6s_cpucode to see how the inputs/outputs of the components connect to each other. - We deliberately gave you more inputs to the forward and hazard units than you might need – do part 1 first, without thinking about the signals, and then think about how your drawings in part 1 can help you identify the logic you need to write in part 2.
- Make use of both the processor view and editor view to see which instructions are in which stage of the pipeline. You can place breakpoints if you want to debug longer programs, and you can right-click on any input/output port to display its value if you need to see a specific signal in more detail – read the Ripes documentation (linked on the resources page) for more information on navigating Ripes.
Part 0:
Perform a git pull in the Ripes directory and read through part 3 of the pipelining notes, as described above.
Part 1: Identifying hazards
For each pipeline, draw two pipeline diagrams (four diagrams total), similar to those in the pipelining notes for the 5s processor. The first diagram should show what happens with a control hazard (branch and/or jump instruction). The second diagram should show the possible data hazards and how they’re resolved with forwarding and/or stalling. Put all of the diagrams in a single PDF file (to make them easier to grade).
Your diagrams should be structured similarly to the ones in the pipelining notes/the textbook. Make sure that they include the corresponding RISC-V instructions, and make sure it is clear how each hazard is resolved (via flush, forward, or stall).
Note that you can confirm that code contains a hazard by running it on the given processors (without the forwarding/hazard units) and observing that an incorrect side effect (register or memory write) occurs.
For the control hazard, we are looking for a diagram similar to the one in part 2 of the pipelining notes. For the data hazards, we are looking for a single diagram that communicates all of the possible mechanisms used to resolve hazards. This will likely mean that the example program in your diagram will contain multiple hazards. For our 5-stage pipeline, something like this would be acceptable: Note that this diagram is missing some of the detailed examples from the notes. It gets across the situation that warrants stalling, and it gets across the two different forwarding pathways (ExMem register to Ex stage and MemWB register/RdSel mux to Ex stage), but it doesn't distinguish between all of the sources of the data being forwarded, how "ties" are broken, what sorts of programs *do not* create hazards, etc. It will be up to you to think through these details in order to pass our autograder tests, some of which are hidden for this reason.What are we looking for?
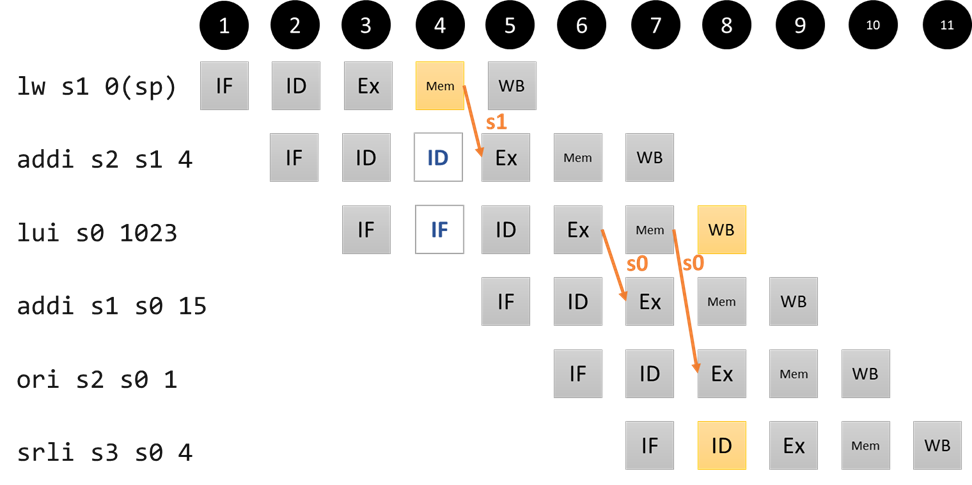
You can use any software you want to draw the pipeline diagrams. If you want to use our powerpoint file as a starter, it is here
Part 2: Implementing the forwarding and hazard units
Using your observations in part 1, complete the code for the forwarding and hazard units. A large part of this task will be understanding the circuit and control signals, based on what we saw in lecture for the single- and five-stage CPUs. Do not modify any files besides cs1952y[4/6]s_[forward/hazard].h – these will be the only Ripes files you turn in, which our autograder will slot into the Ripes repo in order to build your processor. Also, do not add/remove any inputs/outputs from these files. You might find that some input signals should remain unused or some outputs should remain high/low/not use a given Mux selection signal. That’s part of the design challenge of this homework!
Note that it is possible to create a really conservative CPU that just stalls whenever a hazard of any sort is detected. While this would be a working processor (as long as stalling is implemented correctly), it would not be a very efficient processor. Your implementation grade will come not just from the correctness of your processor but from your processors’ ability to stall only when necessary in order to avoid degrading performance.
Part 3: Analysis
Question 1:
One goal of this homework is for you to identify when deeper pipelining is desirable and when the added complexity may be unnecessary. Write two different programs, each of which uses at least one of each instruction in the register/register, register/immediate, memory, and control transfer categories (so, at least four different instructions). The programs should also run for 50 cycles or more. Assume that the 6-stage pipeline clock cycle time is 75% of the 4-stage pipeline clock cycle time. One program should result in a lower execution time for the four-stage pipeline, and the other program should result in a lower execution time for the six-stage pipeline. You will turn these programs into gradescope as 4s_better.s and 6s_better.s. In your PDF file, for each program, briefly explain why the program performs better on one pipeline over the other.
Question 2: (These numbers are adapted from Exercise 4.7 of P&H)
Assume the following latencies for each circuit component:
- Instruction memory/Data memory: 250ps
- Register file: 150ps
- Mux: 25ps
- ALU: 150ps
- Adder: 100ps
- Single gate: 10ps
- Extract bits: 5ps
- Sign extend: 10ps
- Combinational logic units (control, hazard, forward): 50ps
- Register read: 30ps
- Register setup: 20ps
“Register read” is the time needed after the rising clock edge for the new register value to appear on the output. This value applies to the PC and the pipeline registers. “Register setup” is the amount of time a register’s data input must be stable before the rising edge of the clock. This value applies to the PC and the pipeline registers. The register file doesn’t use register read/setup – all of its operation (including bypass) is encapsulated in the 150ps figure above.
Based on these numbers, what is the minimum clock cycle time of the five stage CPU from the notes? In your PDF file, show your work by indicating the worst-case path for each cycle on the diagram or by writing it out.
Question 3: (Adapted from Exercise 4.11 of P&H) RISC-V is a load-store architecture, which means that all computations are done on registers. Let’s explore what would have to change about our processor if we allowed a single instruction to compute an arithmetic result and store it to memory: consider a “store sum” instruction (ss rs1, rs2, imm) whose behavior is: Mem[Reg[rs1]]=Reg[rs2]+immediate. Answer the following in your PDF file:
a. Using our single-stage processor in Ripes as a starting point, draw out what the path of this instruction would look like through the circuit. If you need to add any new components or modify existing components, indicate that in your diagram/in a short explanation. Also explain what new signals (if any) are needed from the control unit to support this instruction.
b. Give an example of a program where the use of the ss instruction introduces a data hazard in the five-stage processor. Explain how the current forwarding/hazard units are able to take care of this hazard, or briefly describe how the units would need to be changed to account for this hazard.
Part 4: Reflection
At the end of your pdf, include your answers to the following questions:
- What were your main takeaways from this assignment?
- What suggestions do you have for improving the assignment in the future?
- What questions do you still have about pipelining/CPU design?
Handin
Your submission should include the following files, all made to the same Gradescope submission:
- Your implementations for
cs1952y[4/6]s_[forward/hazard].h(four files) from Part 2. - Your
4s_better.sand6s_better.sprograms from Part 3. - Your pdf, which should include: your answers to part 1, your answers to part 3, and your reflection from part 4.
Changelog
This will be updated whenever any clarifications have been added to this assignment. See also the FAQ on Ed!
- 2/11/2025 9:39 am: First analysis 6s cycle time changed to 75% of 4s cycle time
- 2/11/2025 10:54 am: clarified register file timing