Building a five-stage pipelined CPU in Ripes (Part 2 -- Control hazards)
Previously: Five-stage CPU part 1; Next: Five-stage CPU part 3
Step 2: Handling control hazards
Whenever our single-stage CPU had to jump or branch, we were guaranteed that the PC would get set to the correct address on the next cycle. This is because all computations happened in one cycle, including the arithmetic to compute the new PC address and the logic to determine what value should go into the PC register for the next cycle. In our five-stage pipelined processor, both the ALU result (required for computing branch outcomes) and the PC+imm computation (required for computing jump/branch targets) happen in the Ex stage. The branch/jump logic that uses these results thus happens in the subsequent (Mem) stage. At the same time, the IF stage fetches a new instruction on every cycle. We’ll explore the consequences of this now.
Observing a control hazard
Consider the following code:
addi s0 x0 1
addi s1 x0 3
jal addReg
addi s0 x0 5 # should be unreachable
addi s1 x0 6 # should be unreachable
addi s2 x0 1
addi s3 x0 1
addReg:
addi s2 x0 1
addi s3 x0 1
addi s4 s0 9 # should be 10
addi s5 s1 9 # should be 12
What values do s4 and s5 have at the end of this program? Stepping through the pipeline, when does the PC get updated with the jump address? Take a minute to build the step1 code and actually observe this now.
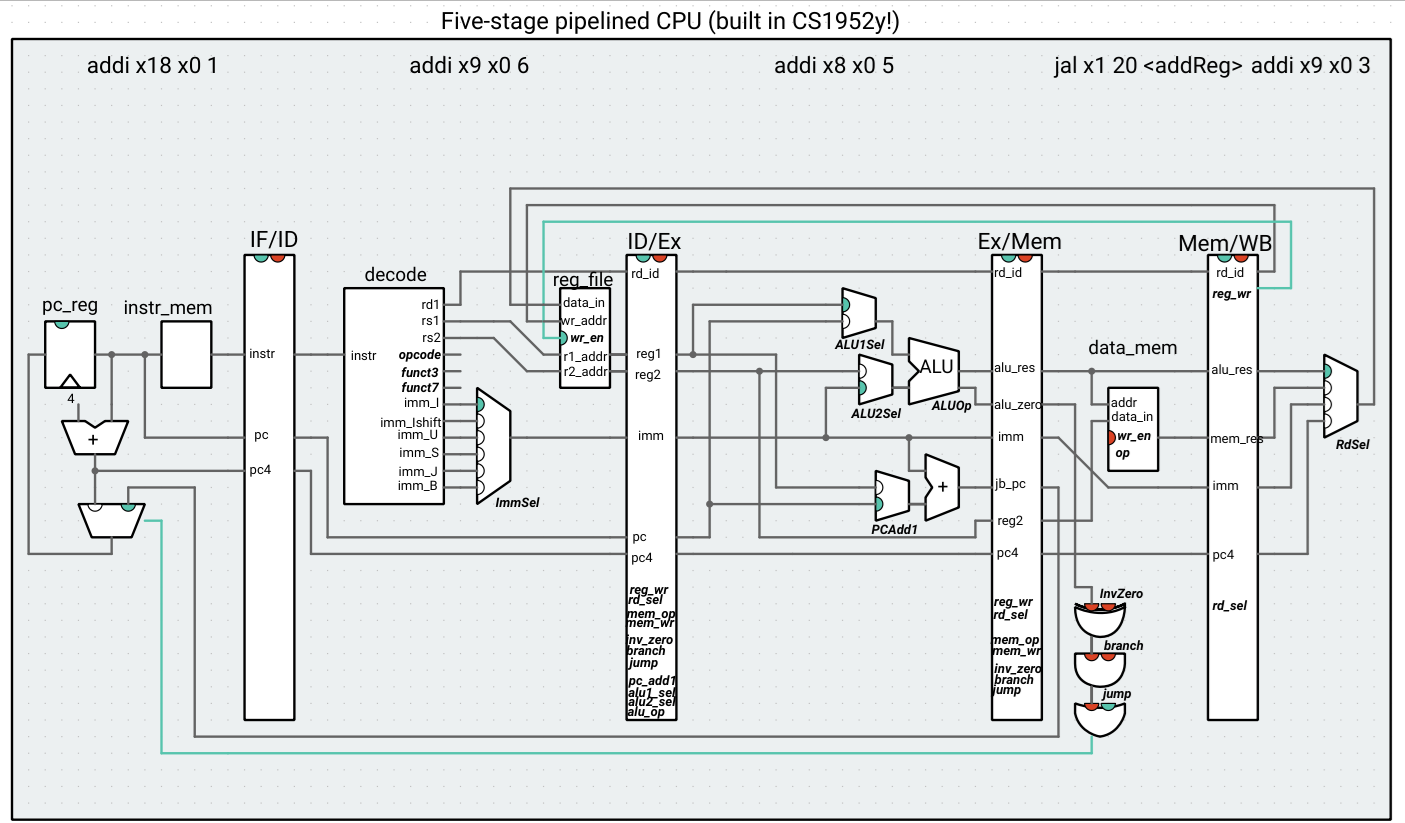
The different views in Ripes are helpful for making sense of what’s going on. In the processor view, we see that the output of the branch/jump gate logic in the Mem stage is high only when the jal instruction reaches the Mem stage:
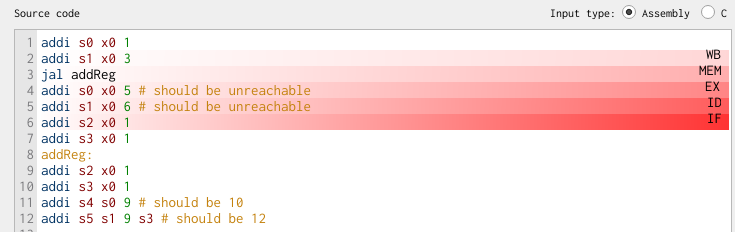
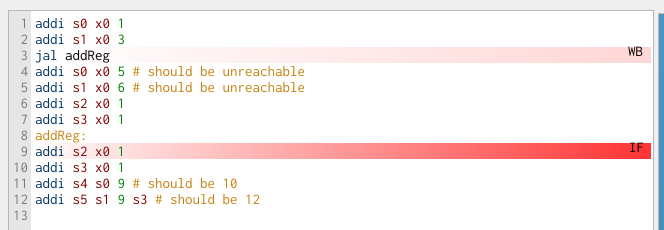
In the editor view, we can see that the subsequent three instructions are in the pipeline already:
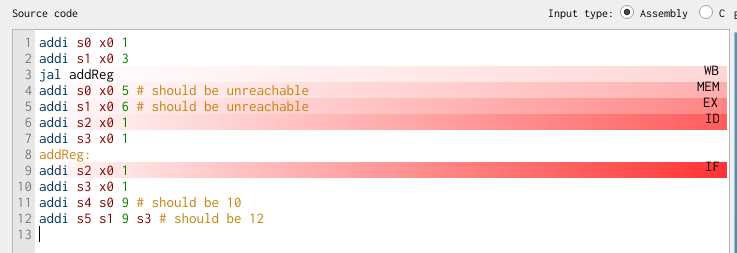
If we advance by one clock cycle, only then does the instruction at the addReg label enter the pipeline at the IF stage (skipping over the instruction on line 7 only, when we want our execution to skip lines 4-6 as well):
Flushing the pipeline
We can see that the pipeline continues fetching subsequent instructions while the jump address (or branch address and decision!) are being computed. For this reason, the RISC-V reference manual recommends that code be optimized so that branches are unlikely to be taken. If the branch does get taken, we need some way of flushing the instructions that were in the pipeline between the branch instruction and the IF stage where the PC changes to the branch destination address. For simplicity’s sake, we will do the same with jumps – since jump instructions rely on the Ex stage to compute the new PC, we won’t bother distinguishing between when we deal with branches and jumps. Indeed, we will rely on the input to the mux that selects the new PC (the output of the OR gate in the Mem stage) to detect when we need to flush the pipeline.
How do we flush the pipeline? We will rely on the enable and clear control signals of the pipeline registers (they are indicated at the top of each register – so far, enable has always been high, and clear has always been low). For a clocked register, driving the enable signal low means the register is unresponsive to the input (that is, hangs on to its previous internal state). Typically, we drive the enable signal low to keep the register from changing its output for one or more clock cycles. Driving the clear signal high means the register produces a 0 for all of its outputs at the start of the next cycle. In particular, this means that the reg_wr and mem_wr signals would change to 0 (and get passed along the rest of the pipeline as such), meaning that there are no permanent side effects (register or memory writes) where an instruction got cleared. We don’t really care about what happens to the rest of the data in a pipeline stage as long as it doesn’t have a side effect, so clearing the entire register is the easiest way to clear the signals being passed along. Because we see that three instructions are loaded into the pipeline that shouldn’t be (one each in the IF, ID, and Ex stages when the jump/branch outcome is detected), we need to clear IF/ID, ID/Ex, and Ex/Mem registers to prevent those instructions from proceeding along the pipeline.
Why do we clear these registers at the same time, instead of, for example, allowing the instruction in the IF stage to proceed through the pipeline until it reaches the Mem or WB stages? It comes back to thinking about this in terms of hardware and how the circuit is running. At some cycle, the jump-or-branch signal will go high, and we need to act on preventing the hazards when this happens, not in some later cycle.
Pipeline diagram for our control hazard
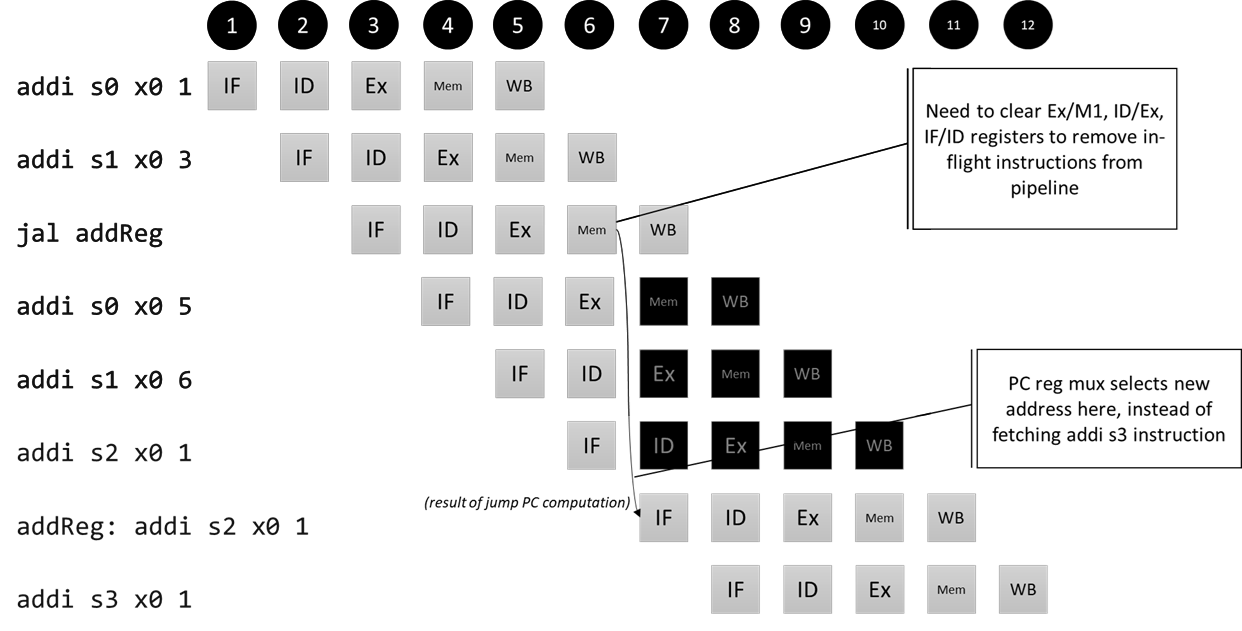
We don’t need a new component (for now) – we can just connect the output of the jump-or-branch OR gate to the clear signals of the pipeline registers!
j_or_b->out >> ifid_reg->clear; // same for idex_reg, exmem_reg
In the picture below, we’ve explicitly included the j_or_b connection to the clear signal of the IF/ID register (but avoid cluttering the picture even more with connections to IDEx and ExMem. However, keep in mind that those connections exist). The best way to check if a register is being cleared is by looking at the right-side indicator at the top of each register. If the indicator is red, the clear signal is LOW (so the register is passing data through like normal), and if the indicator is green, the clear signal is HIGH (so the register will output 0s for all signals on the next cycle).
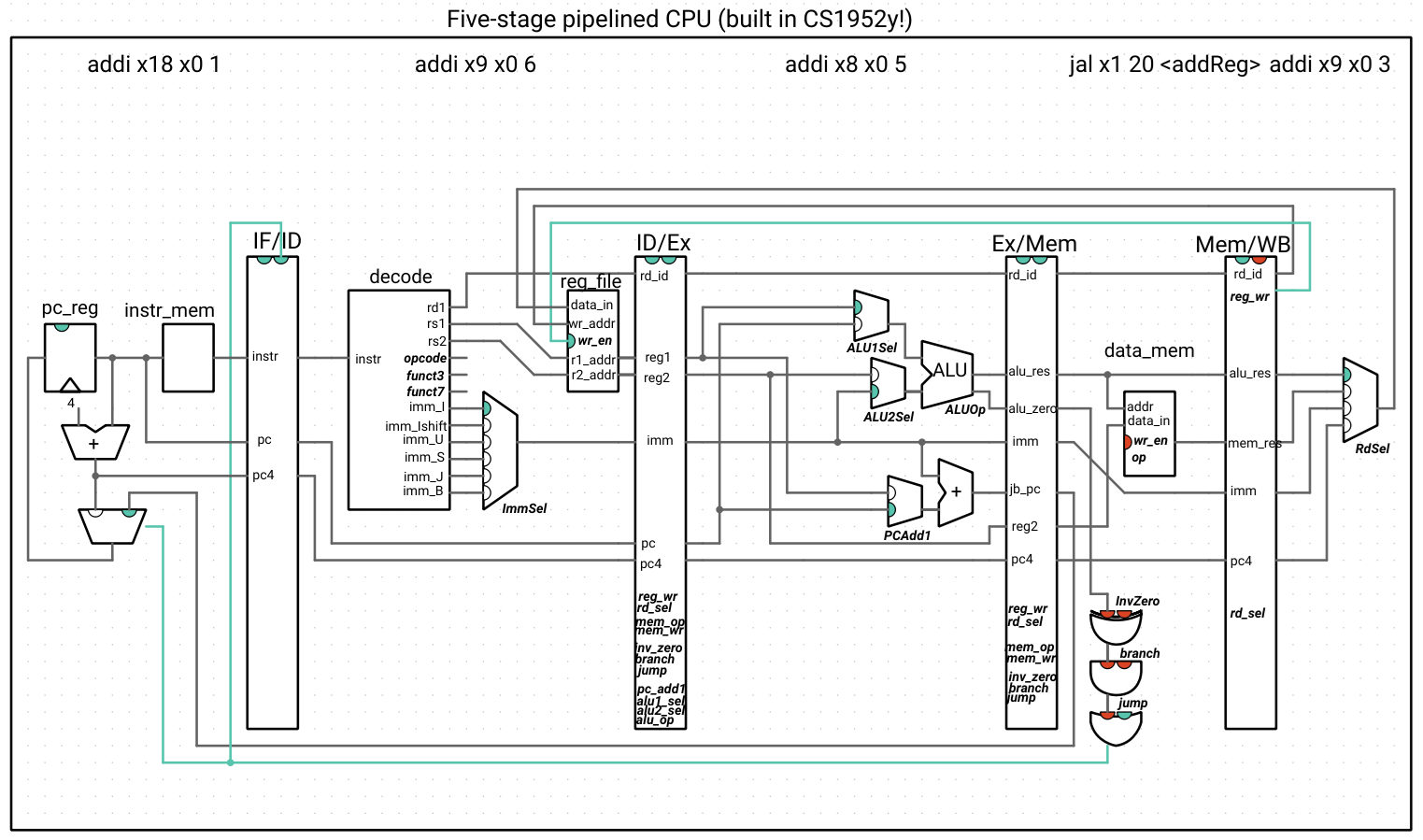
Now we see that, when the jal reaches the mem stage, all of the clear signals in the hazard unit are high, and in the next cycle, the pipeline is flushed, with the instruction at the addReg label in the IF stage:
You might be thinking that jump and branch instructions almost cancel out the whole point of pipelining, since flushing the pipeline means that portions of the CPU aren’t doing meaningful work until the new instruction is fetched. You would be right! It turns out, branching is a problem that computer architects have spent years thinking about. We’ll revisit strategies for dealing with this, such as branch prediction, later in the semester. For now, we move on from control hazards to data hazards. We will want to avoid inserting periods of idleness into our processor as much as possible, which leads to our discussion of forwarding.