Homework 3: Cache Assignment in gem5
Due: Friday, 3/7 at 10pm
Overview
In this assignment, you will implement a writeback cache from scratch and use it to simulate real programs in gem5. This will allow you to evaluate your cache under different workloads and with different configurations. There will be a few iterations of your implementation, where each step is designed to build on the previous step. You will only submit the code associated with the final iteration to Gradescope, but you will also submit a written component that you will answer as you go.
gem5 is a complicated tool. Using it or extending it straight out of the box can be tricky, so it will be useful to examine the gem5 cheat sheet and/or revisit the gear-up session recording and slides (all on the resources page) in order to familiarize yourself with the tool. Feel free to come by office hours for further clarifications, but note we may refer you to the available resources if we believe the answer can be found there!
Stencil code
Get started by cloning the repo if you are working locally or pull the latest version if you are working in the course Docker container! The files that you will need in this assignment are src/mem/cache/micro-cache.{hh,cc}.
Running the simulation
We provide two configuration files in configs/assignments/cache for running your code. The first is cache-assignment.py. Run
build/RISCV/gem5.debug configs/assignments/cache/cache-assignment.py -h
To see the options. For the binary, you can find some compiled binaries in tests/test-progs/cache-tests, and you can also try out some of the pre-compiled RISCV binaries that come with gem5, such as tests/test-progs/hello/bin/riscv/linux/hello. The --control flag will run the built-in gem5 cache instead of your cache, which can be helpful for seeing what the gem5 output usually is for a given binary.
The second configuration is traffgen.py, and you can similarly see its options using the -h flag. We’ll talk about it below.
Submission and grading
You will upload a written and programming component to one Gradescope assignment. The written component should be uploaded as a PDF. For the code, upload the micro-cache.{hh,cc} files. You will also be submitting json files to the “HW3 Cache Profiling” Gradescope assignment, but we will not directly grade those jsons.
We will run some basic autograder tests on your code (such as checking that a higher-latency cache performs worse than a lower-latency one), all of which will be visible to you. We will also check your code manually to make sure that it conforms to the directions put forth in this handout. Finally, we will grade your responses to the written questions to assess your conceptual understanding of caching.
Part 0: Protocol Description
Before starting to code, read through this assignment handout and make sure you understand the general role of the cache you’re being asked to implement. To guide your work, sketch a finite state machine controller for the cache protocol that deals with CPU requests (i.e., you don’t have to describe the coherence protocols). The state machine is driven by the handleRequest and handleResponse callbacks (i.e. your transitions should happen based on the information from these functions). You do not have to turn this in, but we will ask you for it to help us check your conceptual understanding when you ask us questions. Your state machine should be complete enough that the pseudocode for the assignment should follow. It doesn’t need to be wholly exhaustive, but you should enter the state machine at a starting state, and consider the following questions:
- What sort of signals does the cache need to keep track of?
- Is the request a read? Write?
- Does the request hit in the cache given the current state?
- What should be sent to memory and when? What should happen on the response?
Why an FSM?
A cache is a complicated mechanism that may take several steps for a specific action. A finite state machine allows you to express the order in which these steps happen. For example, caches might wait for a response from memory before being able to do some next step, and this sort of behavior is straightforward to express in a "wait state" of an FSM. For a more detailed overview, check out section 5.9 of P&H!
Part 1: One-Block Cache
In the first part of this assignment, you will implement a cache that will only ever consist of a single 64-byte block, based on this study. The aim of this part of the assignment is to familiarize you with the gem5 environment, and evaluate the impact of having a single block cache in terms of performance with different benchmarks.
In the micro-cache.cc file, you will see that there are two functions for you to complete: handleRequest and handleResponse. For the cache to work, these functions need to implement well-defined behavior, which should conform to your state machine as described in Part 0.
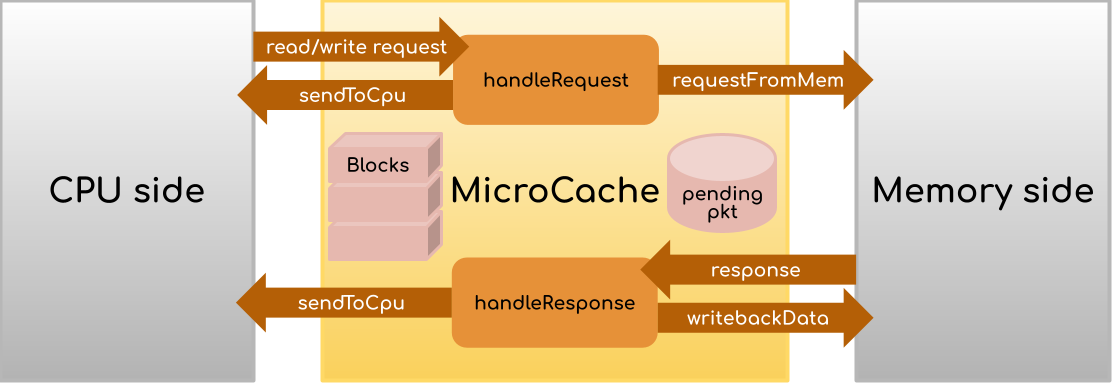
The cache-assignment.py config file situates the MicroCache as an L2 cache connected directly to DRAM on the memory side. The L1 D- and I-caches use the existing gem5 implementation and both make requests to the MicroCache. However, theoretically, the MicroCache could be plugged in to any level of the hierarchy and still work, because read/write requests will only ever come from the CPU side of the hierarchy.
handleRequest receives a PacketPtr (i.e., Packet *) from the CPU, and will perform either the hit or the miss routine. The hit routine occurs if the data being searched for resides is currently in the cache. Otherwise, perform the miss routine, which keeps a pointer to the Packet around (using the pending field) to refer to when a response comes back from memory. In either case, handleRequest should increment the stats.hits or stats.misses counter in order for your assignment to be graded!
On the other hand handleResponse should perform the post-memory access routine. That is, the pkt in the function arguments is the response of a memory request (that you will create!), and not the CPU request. Remember, your response may need to replace some existing data in the cache, so be sure to handle this case appropriately!
Details
You may assume that CPU-side requests will not cross block boundaries (i.e. you will not need to fetch multiple blocks to service a single request). The block size (and therefore the size of requests to memory) is 64 bytes, so make sure that any requests to the memory side are aligned at 64-byte boundaries. For now, ignore the size and assoc fields of the MicroCache class.
Your implementation must heed the following:
- You should ensure that only one memory request can occur at a time by setting the “blocked” flag. This includes writeback requests – we do not want to process requests while data is being written back. The
writebackDatafunction (imp) - You should ensure that all cache accesses apply a latency by using
schedule(see examples in the scaffolding). The buses and RAM will incur a latency of their own, but we need to make sure that any L2 access is modeled with its own latency!
We’ve implemented a few helper functions for you in micro-cache.hh. For communication with the CPU, if the handleRequest function returns false, the CPU needs to eventually be told to retry the request. The unblock function (which is called from sendToCPU or can be called/scheduled by itself) does this for you. For communication with memory, the requestFromMem and writebackData functions set up the requisite packets, which then need to be deleted (the scaffolding in handleResponse does this for you).
We have also provided a Block struct for you. For the single-block cache, you only need to allocate one block and keep its fields updated throughout execution.
Overall, gem5 uses a lot of objects that use a lot of functions – many of which are not relevant to this assignment. Full listings of packet functions can be found in the src/mem/packet.hh header, or in the formal documentation. For your convenience, here are some functions that you may find useful:
- Addr Packet::getAddr() (e.g.,
pkt->getAddr()): returns the address of the current packet. Note, Addr is an expansion of uint64_t - unsigned Packet::getSize() (e.g.,
pkt->getSize()): returns the size of the current packet. - bool Packet::isWrite() (e.g.,
pkt->isWrite()): returns true when the current packet has data to write to the relevant block. (also,pkt->hasData()should return true here) - bool Packet::isRead() (e.g.,
pkt->isRead()): returns true when the packet should read data from the relevant block - *T* Packet::getConstPtr
()* (e.g., `pkt->getConstPtr<uint8_t *>()`): returns a pointer of type T to the data stored in the packet - void Packet::writeData(uint8_t *p) (e.g.,
pkt->writeData(p)): sets the data stored in the packet to the pointer p. - void Packet::setData(const uint8_t *p) (e.g.,
pkt->setData(p)): sets the data stored at pointer p to the packet. - bool Packet::needsResponse() (e.g.,
pkt->needsResponse()): returns true when the current packet should be returned to the CPU with the relevant fields updated (data should be set to the packet if it is a read, etc)
Testing
Once you have finished, be sure to test your cache against each of the sample test binaries as described above! If your simulation crashes or if your simulations hangs (i.e., runs for more than 5 minutes without finishing) be sure to check out the Common Errors section of the gem5 cheat sheet.
The gem5 gearup has resources on using gdb to debug gem5. You can also put DPRINTFs in the code with the MicroCache flag (e.g. DPRINTF(MicroCache, "This is my cool debug message")) enable the MicroCache debug flag on a run using build/RISCV/gem5.debug --debug-flags=MicroCache configs/.... Note that the --debug-flags flag does before the config script.
Note from the staff: we’ve tried our best to provide statically compiled binaries that work with all environments (local, docker, autograder). If you find that one or more of the binaries are crashing when you use the --control flag, please make an Ed post and we’ll look into it. If a binary runs with the --control flag but not without, that means there’s an issue with your MicroCache implementation.
Part 2: Profiling
We’ll move on to enlarging our cache in a bit, but first, let’s reason about the effects of cache size and associativity on performance. In class, we’ve seen (and will continue to see) a few examples of real-world specs, such as sizes for modern L1, L2, and L3 caches. Sometimes, the manufacturers of the computers provide these specs, but other times, they are hidden from the consumer. How do people find out these specs? By running some sort of workloads on the computer and observing their effects on performance. For this part of the assignment, you will do the same.
We have given you a config file called traffgen.py, which invokes a TrafficGenerator (src/cpu/testers/traffic_gen). The traffic generator directly generates read/write requests, and by hooking it up to our MicroCache, we can directly measure its performance without relying on the complications of a CPU and L1 D- and I- cache in the way. traffgen.py has two required arguments: mode (linear, random, or strided) and read percentage (0-100 inclusive). We can also optionally pass in the (exclusive) max address (e.g. 128B, 1kB, 32MB, etc, not to exceed 512MB), the number of requests we want to make, and the request size in bytes (not to exceed 64, or the block size). The random generator makes random requests for addresses between 0 and the max address, and the linear generator makes linear requests (incrementing the address by traffic_request_size bytes for each request), wrapping back around to 0 if it reaches the max address. The strided generator uses its own option, traffic_stride, and always makes 64-byte requests, traffic_stride bytes apart (so if traffic_stride = 128, the first request will be at address 0, the second at 128, then 256, and so on). For example, try out this command:
build/RISCV/gem5.debug configs/assignments/cache/traffgen.py linear 100 --traffic_request_size=16 --traffic_num_reqs=100
If you take a look at m5out/stats.txt and locate l2cache.hits and l2cache.misses, you should see exactly 25 misses. Why is that?
If you’re playing around with the traffic generator and want to understand the sequence of addresses that will be sent, you can get more detail by putting --debug-flags=TrafficGen before the config script to observe the addresses sent. Keep in mind that addresses are displayed in hex.
If we hook the traffic generator up to a mystery cache and play around with the mode, max address, number of requests, and request size, we can derive the size and associativity (number of blocks per set) of the mystery cache. The gradescope assignment “HW3 Cache Profiling” allows you to do that. You will submit a .json file providing these four fields, using this exact format (all fields optional; default values are as below):
{
"mode": "random",
"max_addr": "512MB",
"num_reqs": 1,
"req_size": 64,
"stride": 64
}
The autograder output will report the number of cache hits and misses.
A few notes:
- The block size of the cache is 64 bytes, so the request size should not exceed 64
- We make no guarantees about what will happen if your numbers are not powers of 2
- There are multiple different cache configurations, assigned using a very complicated formula on your student id, so you can’t just ask your friend what they measured
Because the autograder takes a while to run, you can submit multiple json files (in different submissions) and use Gradescope’s “submission history” to view the results for each oneHowever, to encourage you to think about this task strategically, you are limited to three submissions per hour (due to autograder infrastructure limitations, this includes submissions that are rejected due to formatting issues. Sorry! Make sure to double-check your json format before submitting.)- Unfortunately, due to how the autograder stores user data, only one submission from a user can be running at a time. There is no limit to how many times you can submit, but you shouldn’t submit multiple times before the autograder finishes running.
- If the autograder gives a message about gem5 not being able to run, make sure your request size is between 8 and 64 and make sure your max_addr is formatted correctly, is not less than 64B, and is not more than 512MB. Please also make sure your mode is one of linear, strided, or random
- For the strided generator, req_size is ignored (requests are always 64 bytes). Make sure stride is a multiple of 64, so that requests do not cross block boundaries. The linear and random traffic generator ignore the stride option
- The mystery caches can be anywhere from 1kB-512kB (inclusive, and always a power of two kBs) and can range from direct-mapped to fully-associative to anywhere in between
A: In your pdf file, provide a guess for the cache size and associativity of your mystery cache and back up your reasoning using the results you observed.
B: In the real world, the computer doesn’t simply spit out a miss rate and hit rate after you run a workload. Run the cache-assignment.py config with the built-in cache (using the --control flag) and a couple different size and associativity parameters. Take a look at what is reported by m5out/stats.txt for prog1, prog2, and prog3. Based on what each programs is doing, are you able to observe the effects you expect? What stats are most useful? (You don’t have to write any answers down here/report any stats. It’s meant to kick-start your reasoning for the subsequent paragraph.)
In your pdf file, explain how you think cache size profiling is actually done. How do you account for complicating factors such as multiple levels in the memory hierarchy, multiple processes, etc? We’re not looking for you to get this 100% right, but we want you to demonstrate understanding of computer performance metrics and of the various factors that affect how a workload interacts with the memory hierarchy. If you read sources on the way to answering this, please cite them (actual sources, not just ChatGPT).
Part 3: Caches with sets
Your cache implementation may well be fully functional after Part 1, but realistically it’s not super usable. Let’s add some capacity to this cache so that we can store more than 64 bytes at a time. As we learned in class, caches of a given capacity and block size can be organized multiple ways using sets.
Your implementation should use the size field (an integer that specifies the size of the cache in bytes) in the constructor of the MicroCache, and allocate the appropriate amount of space for each of the blocks. Ignore the assoc field and start with a fully-associative cache, that is, one where an address can map to any block (i.e. the cache is made up of one large set). Test it out and then use the assoc parameter to customize the associativity (number of blocks per set) of the cache. You will have to do some math here to figure out how to track the number of sets. You can assume that the size/assoc configuration will be reasonable (assoc a power of two, allows for sets that are an integer multiple of block size).
The handleRequest function will now have to search across the blocks in a set in order to determine whether or not to follow the hit or miss procedure. Make sure you’re only searching in the required set. How can you adapt the math we learned in class to use the request address to index into the appropriate set? (You can also refer to section 5.4 of P&H to review this conceptually).
The handleResponse function now needs to choose which block to fill the new data. In this case, we would like to:
- Fill an empty block if one exists; or
- Choose a block in the cache to evict in order to make space for this new data to fill.
There are several ways to choose the block to evict. You should implement the least recently used (LRU) eviction policy. That is, in scanning for a place to place the new data, you should track which block is the one that has been used the least recently. Then, write this data back to lower levels of the cache hierarchy as done in Part 1. To do this, you should modify what is stored with each cache block in the micro-cache.hh file, and update this timestamp with the curTick() each time the block is accessed.
Be sure to use the config scripts and what you’ve learned in part 2 to test out your cache!
Least recently used is far from the only possible replacement policy. In fact, there are several other replacement policies, including: least frequently used, time-aware least-recently used, most-recently used, etc (to read more, see here). From this list, choose one alternative time-based replacement policy and then choose one frequency-based replacement policy to use in the reflection section.
Reflection
Include the answers to the following questions in your PDF
A: Figure 5.18 of P&H shows that the implementation of a set-associative cache involves a parallel comparison between the tag of the desired address and the tags of all of the blocks in a given set. In code, you probably implemented your set by searching through the tag fields of each block in the set in some way. This would imply a linear code runtime growth with respect to the number of blocks in the cache. Because gem5 is simulating hardware, it does not simulate timing by measuring the runtime of the simulation code. Instead, as you saw, it uses latency parameters to schedule events. For example, we could set the latency to 20ns in the single-block cache from part 1, and set it to some different number for our fully-associative cache to take into consideration the additional changes to hardware. If you wanted to assess different caching configurations using gem5, how would you go about choosing this number? Think about justifying one type of cache vs. another to your boss using these numbers – what evidence would you need to provide to support the numbers gem5 reports? What limitations of the comparison would you need to explain to your boss?
B: Suppose you have 4 block fully associative cache. Come up with a memory trace (a sequence of address and operation types) for which the LRU replacement policy is sub-optimal compared to your selected alternative replacement policies. Then provide a different memory trace for which the LRU policy is optimal compared to that same trace.
C: Going back to Figure 5.18 of P&H, the data from each block in a set is being routed to a multiplexer whose selector uses the result of the tag comparison. Because at most one block will match the tag we’re looking for, the circuit is wasting energy transferring data from all of the blocks in the set. The more associativity we have, the more energy this is going to use. One approach for dealing with this is way prediction (original paper), which predicts which block in the set will be a hit (the paper uses a most-recently-used scheme), and starts transferring only that data while the tags are being compared. If the prediction is wrong, then the circuit is updated to select the correct data line. This misprediction introduces some delay, but saves energy – in the worst case, two data lines will be active for a cache access.
C-1: What additional field(s) would you need to add way prediction to our cache in gem5? How would you ensure that you’re accurately modeling the delay incurred by a way misprediction?
C-2: The original paper models energy usage using some approximations based on prediction hit rate (see formula 7), uses a cache simulator to measure the prediction hit rate, and reports estimates of energy savings based on these two things. The paper was written in the 1900s. These days, gem5 supports power modeling, with the caveat that “the definition of a power model is quite vague in the sense that it is as flexible as users want it to be.” This video (13 minutes) shows how folks at arm use gem5 for power modeling. Given that way-prediction involves optimizing the use of specific wires, some thermal modeling would need to be done to compute the energy savings from way-prediction in gem5. Are you convinced by the way energy modeling done in the original paper? If someone created an updated version of that paper that reported numbers from gem5 power modeling, what evidence would you need in order to believe that the gem5 power modeling produces more accurate results than the original paper?
D: Your fully associative cache allows only a single memory access into the cache at a time. This helps us simplify working with multiple memory operations in order for our hardware to maintain clean memory consistency. Suppose we had multiple responses at the same cycle, and both needed to choose a block to evict. In our current implementation, both would choose the same block and the second would overwrite the first without keeping both values in the cache at the same time. This would be bad!
However, our current means of blocking is wholly inefficient with multiple sets. If two memory requests occur in different sets, then there is no need for one to block out the other’s execution.
D-1: One solution is for each set to have its own blocking flag. What would need to change in order support parallel hits? What about parallel misses? How would you suggest that the cache controller synchronizes this logic?
D-2: What you have described in the previous part is a lightweight miss status holding register (MSHR) which is a hardware primitive used in real caches (blocking and non-blocking) in order to maintain the global memory consistency model handling parallel misses for similar and dissimilar addresses in memory. What is the relationship between maximum achievable parallelism in a cache (i.e., the bandwidth of a cache) and the number of MSHR registers that the cache can support? It may help to justify your answer with an example.
Handin
Your submission should include the following files, all made to the same Gradescope submission:
- Your implementation for the
micro-cache.{hh,cc}from Part 3 - Your pdf with your written responses from Part 2 and the Reflections section
Changelog
This will be updated whenever any clarifications have been added to this assignment. See also the FAQ on Ed!
2/22/2025 11:52am: added context for debug flags 2/28/2025 11:26am: changed assumptions for profiling autograder